Delphi FAQ - Часто задаваемые вопросы
| Базы данных |
Графика и Игры |
Интернет и Сети |
Компоненты и Классы |
Мультимедиа |
|
ОС и Железо |
Программа и Интерфейс |
Рабочий стол |
Синтаксис |
Технологии |
Файловая система |
|
DBTreeView своими руками
Автор: Елена Филиппова Введение В статье речь пойдет об отображении данных, хранящихся в БД и имеющих иерархическую (древовидную) структуру. Визуальное представление таких данных требует соответствующего инструмента. Существует немало компонент, которые позволяют представлять данные в виде дерева — для краткости будем называть их все DB TreeView. Компоненты эти довольно удобны, но, как правило, "заточены" под определенные задачи и каждый "шаг в сторону" в структуре данных заставляет многих пускаться в поиски. И на Круглом Столе появляются вопросы: "помогите найти компонент DB TreeView, который позволяет делать еще и ..." и так далее. А ведь в Delphi существует стандартный компонент для представления древовидных данных, это знакомый всем TTreeView, его возможностей хватает с лихвой практически для всех задач по отображению деревьев. Сделать из TreeView самый настоящий DB TreeView, да еще полностью контролировать его развитие, более перспективный путь, нежели каждый раз искать новый чужой компонент. Весь этот материал основан на моем личном опыте и, естественно, не обязательно является самым оптимальным вариантом. Это частное мнение, которым я просто хочу поделиться. Рассмотрим два принципиально разных случая:
Отличаются эти примеры стуктурой данных и, соответственно, способом формирования дерева. Тем не менее сущестуют общие правила для генерации дерева. Во-первых, я исхожу из предположения, что все дерево сразу с большой степенью вероятности не понадобится пользователю. Более того, сам процесс формирования TTreeView довольно длительный и занимает ощутимое время, особенно если работать с большим объемом БД. Гораздо правильнее строить отдельные ветки дерева динамически, только в тот момент, когда они наверняка понадобятся. То есть, в самый начальный момент необходимо сформировать только самый верхний уровень дерева. Затем, по мере требования, можно достраивать очередную ветвь. Какой же момент можно считать моментом требования? В принципе есть два равнозначных варианта и отличаются они только внешним видом.
Основное отличие этих подходов: в первом случае пользователю необходимо сделать явно лишнее и не очень естественное для дерева движение , то есть двойной клик. А во втором случае мы должны обеспечить возможность раскрытия для каждой ветки дерева, ведь если у ветви нет значка [+] , то и попытаться раскрыть ее будет невозможно. А значит для всех новых, свеже сформированных ветвей, принудительно нужно обеспечить существования фиктивной дочерней ветви. Можете сами выбрать, что Вам удобнее, я использую второй вариант. На сервере http://ib.demo.ru/ была опубликована статья Кузьменко Дмитрия "Древовидные (иерархические) структуры данных в реляционных базах данных", часть которой посвящена теме визуального представления древовидных данных. В этой статье предлагалось хранить в таблице дополнительное поле с количеством дочерних записей для каждой ветви именно для того, чтобы иметь возможность принимать решение рисовать или не рисовать знак [+] возле текущей ветки дерева. То есть на ходу определять, имеет ли шанс эта ветка быть раскрытой. Следовательно, только для процесса визуализации требуется изменять структуру данных, добавлять триггеры для сохранения целостности дополнительной информации. Каждый способ имеет свои достоинства и недостатки, но мне кажется несколько неоправданным такой подход, когда структура таблиц зависит от способа их отображаения. В примерах, которые иллюстрируют материал этой статьи применяется использование фиктивных дочерних ветвей для обеспечения появления у каждой ветви значка [+]. Примечание:
Такой вопрос, как способы представления иерархических данных в БД, не является предметом данной статьи. Дерево подразделеений Пусть у нас существует таблица подразделений, каждое из которых может иметь свои внутренние подразделения. Необходимо отображать эти данные в виде дерева. Используемая в примере таблица — COMPANY.DB Структура данных реализована классическим деревом: каждая запись о подразделении представлена полями
Для тех подразделений, которые не имеют головных над собой, поле ParentID равно 0. Формировать уровни дерева мы будем с помощью запроса к таблице ( компонент qTreeCompanies : TQuery ).
Параметр ParentID будет определять, какую ветку мы сейчас достраиваем. То есть, к какой ищем дочерние подразделения. Процедура, формирующая очередной уровень (дочерний для ветви Node ) реализована следующим образом:
Теперь позаботимся о том, чтобы она вызывалась в нужный нам момент времени. На событие OnExpanding проверим, есть ли у текущей ветки фиктивная дочерняя ветвь и, если она есть, сформируем реальную ветку, предварительно удалив фиктивную.
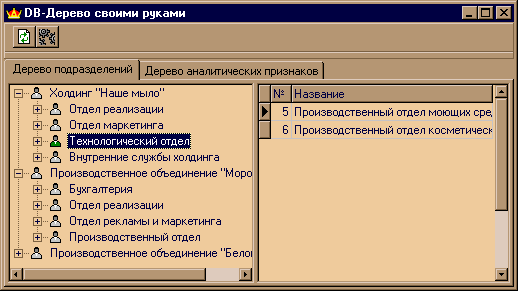 На форме в проекте кроме дерева расположена еще и сетка (Grid), в которой отображаются записи текущего уровня подразделений. Это, по сути, список дочерних ветвей для текущей ветки дерева. Для того, чтобы синхронизировать TreeView и DBGrid используем нехитрый прием — на событие TTreeView.OnChange (шаг по ветке) добавим следующий код:
Помните, в процедуре ExpandLevel мы записывали в поле Data каждой ветки ее идентификационный номер? Вот его то мы сейчас и используем. Для полного ощущения передвижения по Grid'у, как по дереву можно добавить эффект "проваливания" на более глубокий уровень. По двойному клику на записи в Grid'е пользователь проваливается на один уровень вниз по иерархии, если такой уровень, конечно же еще есть. На событие OnDblClick для грида:
Параллельно с этим раскрывается соответствующая ветка самого дерева. Очень эффектно. :о) В проекте реализована возможность добавления новых ветвей, то есть новых подразделений. Нажимте на TreeView правую кнопку мышки и достраивайте наше дерево, как Вам угодно! Дерево аналитических признаков
"Куст — это пучок веток, растущих из одного места" Пусть у нас есть таблица документов, каждый документ, например, описывает некоторую операцию по покупке( или продаже ) товара. В этой операции участвуют: определенный товар, клиент, у которого куплен (или которому продан) этот товар, и город, в котором данная операция совершена. Таким образом, мы имеем таблицу документов, каждая запись в которой наделена тремя аналитическими признаками: Город, Клиент и Товар. По сути своей эти данные не являются иерархическими, и никакой явной зависимости между документами не прослеживается. Но тем не менее эта связь существует — одинаковые аналитические признаки. Например, в одну группу можно объединить все документы, имеющие отношение к определенному товару или клиенту. Если для анализа данных пользователю необходимо работать с документами по зафиксированным аналитическим признакам, то возникает задача визуального представления таких данных. К примеру, заказчик требует показывать ему все документы для определенного города, а потом, для определенного клиента и товара, но в том же городе. Однако желательно видеть информацию ровно в обратном порядке: сначала выбрать документы с нужным товаром, затем увидеть все города, где работали с этим товаром, выбирать нужный город и так далее. Явно прослеживается древовидная структура, где каждый уровень дерева суть аналитический признак. Именно поэтому, как говорилось выше, в данном дереве фиксирована глубина вложенности. Она однозначно определяется количеством аналитики для документа. Описание примера, реализующего данную задачу Используемые таблицы: Таблица документов DOCUMENTS.DB , где каждый документ определен полями:
Таблицы аналитики, соответственно CITIES.DB, CLIENTS.DB и GOODS.DB, содержат поля названия Name и номера (CityID , ClientID , GoodID). 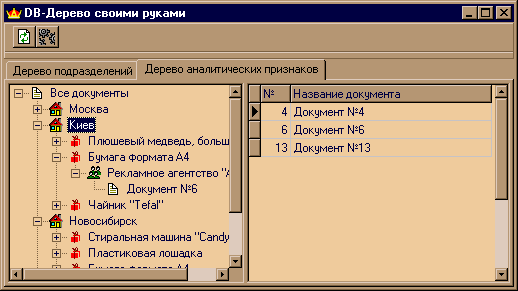 Так как порядок следования аналитики произвольный, зараннее невозможно написать текст SQL-запроса, который будет возвращать данные для очередного уровня дерева. Этот текст придется формировать в run-time, когда все данные будут известны. Чтобы не зашиваться именно на такой список аналитики, который приведен в примере, стоит затратить немного больше сил и обеспечить себе некоторую универсальность. Для этого добавим еще одну таблицу (таблицу сущностей) Entities, содержащую описание используемой аналитики. Поля таблицы ENTITIES.DB
В нашем случае эта таблица будет выглядеть так:
В примере я использую список ListEntities (TCollection), каждый элемент которого содержит поля TableName, KeyColumn и ImageIndex. Элементы в этом списке расположены в том порядке, в каком будет строиться дерево. Заполняется этот список только той аналитикой, которая требуется для конкретного дерева. Например, только города и клиенты или товары и клиенты, или сразу все вместе. Следовательно этот список (ListEntities) и содержит полную информацию для построения дерева в каждый конкретный момент. Заполнение списка аналитики проводится в модуле setupEntities.pas.
Формирование дерева в этом случае полностью аналогично предыдущему примеру, с той только разницей, которая касается формирования текста запроса для каждого уровня дерева. Так же в дерево добавляется единый для всех веток самый верхний корневой узел. С точки зрения аналитики это "фиктивный" узел, так как он будет отображать ВСЕ документы, без указания конкретного значения аналитического признака. Кроме того, достраивается еще один, самый нижний уровень — список документов по зафиксированной для текущей ветки аналитики. Наличие этих "фиктивных" узлов совершенно не обязательно, но, на мой взгляд, очень логично. В итоге, глубина вложенности дерева будет равна "количество аналитики" + 2. Итак, процедура ExpandLevel будет модифицирована следующим образом:
В предыдущем примере мы запоминали ID строки из таблицы в поле Data каждой ветви дерева. Сейчас нам не годится такой вариант, так как аналитический признак определяется не одним идентификатором, а целым элементом списка ListEntities, вот его то и надо запоминать. Поэтому в поле Data сохраняется ссылка на конкретный элемент этого списка. Благо это Pointer и записать туда можно все, что угодно. В процедуре используется функция GetSqlPath, которая возвращает полный путь от корня до указанной ветки дерева. Полный путь это есть зафиксированные значения для каждого уровня аналитики. Эти значения необходимы для того, чтобы верно построить запрос. То есть мы фактически формируем дополнительный фильтр для последующих выборок, напрмер — получаем всех клиентов для конкретного города и указанного товара.
Пример текстов SQL запроса, который будет сформирован при движении по дереву: Уровень "товары" — Все товары, которые встречаются в документах, созданных в городе номер 6 и для клиента номер 3
Последний уровень "документы" — Все документы, созданные в городе номер 6 и для клиента номер 3, по товару номер 1
Такой подход позволяет легко расширять набор аналитических признаков, которые должны использоваться в программе, практически без изменения кода клиентского приложения. Достаточно изменить структуру таблицы DOCUMENTS и дополнить таблицу ENTITIES. В некоторой степени можно сказать, что таблица ENTITIES содержит метаданные о структуре базы. Правда с большой натяжкой, так как в данном примере структура просто элементарна, а связи слишком просты и не поддерживают никакой глубины вложения (как, например, в таком случае, когда город не указан явно в документе, но может быть вытянут из таблицы клиентов и так далее). Для получения набора данных не обязательно использовать именно запросы, точно так же можно использовать хранимые процедуры для SQL-серверных СУБД. Изменится структура метаданных, но не изменится принцип формирования дерева. На мой взгляд, в качестве примера, стоит внимательно рассмотреть такой подход, чтобы вы могли в своих конкретных задачах на его основе конструировать реальные метаданные и без проблем модифицировать дерево аналитических признаков. Итак... Итак, были рассмотрены две принципиально разные задачи, а реализация DBTreeView оказалась практически идентична. Собственно, этот факт и является важным результатом статьи — воспользуйтесь примерами, добавьте собственный функционал и создайте для себя несложный компонент для отображения древовидной структуры. Это не значит, что не стоит пользоваться сторонними компонентами, ни в коем случае. Просто если существующие вас не устраивают полностью, вы будете знать, как это исправить. Для иллюстрации материала статьи подготовлен проект TreeDB : Проект откомпилирован в Delphi 5, использует BDE и настроен на алиас TreeDB |

Copyright © 2004-2026 "Delphi Sources" by «SiteAnalyzer». Delphi World FAQ
