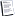
Уважаемый Страдалец, теперь я не смог понять Вас. виной тому
разный уровень мышления и понимания в программировании. У меня
он критически низкий у Вас сравним с Вашим опытом.
Для того, что бы сдвинуть дело с мертвой точки, я постараюсь еще раз, на этот раз очень подробно объяснить задачу, которую решаю. на прикрепленном файле изображено схематичное представление
структуры файла, с которым должна работать программа.
прямоугольниками обозначены т. н. заголовки, в первом самом
большом - описываются общие для всего файла параметры. параметры обозначены окружностями разной формы, потому что параметры разного формата - 2 байтные и 4 байтные.
вслед за большим заголовком, друг за другом, последовательно
следуют "трассы". каждая трасса состоит из своего заголовка, в
котором даются параметры описывающие трассу, также разного
формата. вслед за заголовком идут значения трассы. кол-во этих
значений для всего данного файла - одинаково и оно дается в
первом большом заголовке.
надеюсь теперь со структурой файла все ясно.
суть задачи: необходимо значения всех трасс файла, те что на
схеме представлены кружочками после маленьких прямоугольников -
умножить на 2.
в каком виде это реализовано у меня:
я считываю большой заголовок, из которого узнаю:
число трасс,
число значений, которое у каждой трассы в этом файле ,одинаково.
затем включаю цикл равный числу трасс, в теле этого цикла
я считываю заголовок,
затем включаю второй цикл равный числу значений в трассе,
начинаю считывать каждое значение, значение умножаю на 2.
подобная реализация очень медленная. потому что значений трассы в
одном файле может быть 4000, в другом файле 5000, а количество
трасс - 100 000.
программа будет работать быстрее, если делать ее только для
работы с такими файлами, в которых значения трассы например
4000. тогда использую записи и статичные массивы можно считывать
не каждое значение, а сразу всю трассу целиком.
вот. теперь у меня вопрос как же все-таки сделать так. чтобы
можно было считывать не каждое значение в отдельности, а целиком
всю трассу, и чтобы программа могла бы работать при этом с
файлами, отличающися друг от друга кол-вом значений трасс.
|